Publications
2021
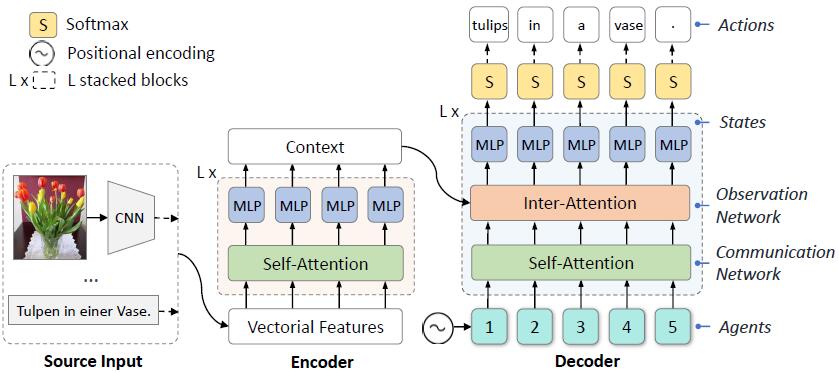 Fast Sequence Generation with Multi-Agent Reinforcement LearningGuo, Longteng, Liu, Jing, Zhu, Xinxin, and Lu, HanqingIEEE Journal 2021 (Under Review)
Fast Sequence Generation with Multi-Agent Reinforcement LearningGuo, Longteng, Liu, Jing, Zhu, Xinxin, and Lu, HanqingIEEE Journal 2021 (Under Review)Autoregressive sequence Generation models have achieved state-of-the-art performance in areas like machine translation and image captioning. These models are autoregressive in that they generate each word by conditioning on previously generated words, which leads to heavy latency during inference. Recently, non-autoregressive decoding has been proposed in machine translation to speed up the inference time by generating all words in parallel. Typically, these models use the word-level cross-entropy loss to optimize each word independently. However, such a learning process fails to consider the sentence-level consistency, thus resulting in inferior generation quality of these non-autoregressive models. In this paper, we propose a simple and efficient model for Non-Autoregressive sequence Generation (NAG) with a novel training paradigm: Counterfactuals-critical Multi-Agent Learning (CMAL). CMAL formulates NAG as a multi-agent reinforcement learning system where element positions in the target sequence are viewed as agents that learn to cooperatively maximize a sentence-level reward. On MSCOCO image captioning benchmark, our NAG method achieves a performance comparable to state-of-the-art autoregressive models, while brings 13.9x decoding speedup. On WMT14 EN-DE machine translation dataset, our method outperforms cross-entropy trained baseline by 6.0 BLEU points while achieves the greatest decoding speedup of 17.46x.
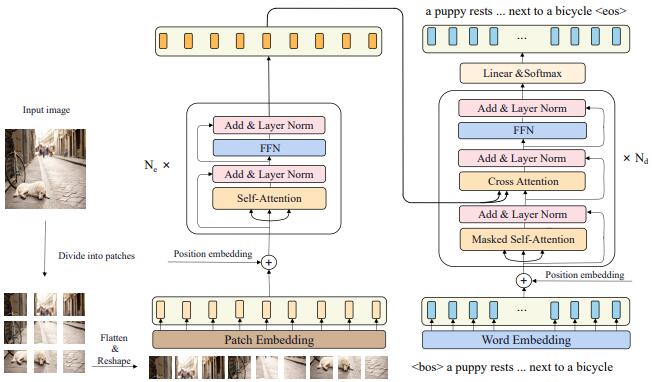 CPTR: Full Transformer Network for Image CaptioningLiu, Wei, Chen, Sihan, Guo, Longteng, Zhu, Xinxin, and Liu, JingIn arxiv 2021 (Under Review)
CPTR: Full Transformer Network for Image CaptioningLiu, Wei, Chen, Sihan, Guo, Longteng, Zhu, Xinxin, and Liu, JingIn arxiv 2021 (Under Review)In this paper, we consider the image captioning task from a new sequence-to-sequence prediction perspective and propose Caption TransformeR (CPTR) which takes the sequentialized raw images as the input to Transformer. Compared to the "CNN+Transformer" design paradigm, our model can model global context at every encoder layer from the beginning and is totally convolution-free. Extensive experiments demonstrate the effectiveness of the proposed model and we surpass the conventional "CNN+Transformer" methods on the MSCOCO dataset. Besides, we provide detailed visualizations of the self-attention between patches in the encoder and the "words-to-patches" attention in the decoder thanks to the full Transformer architecture.
2020
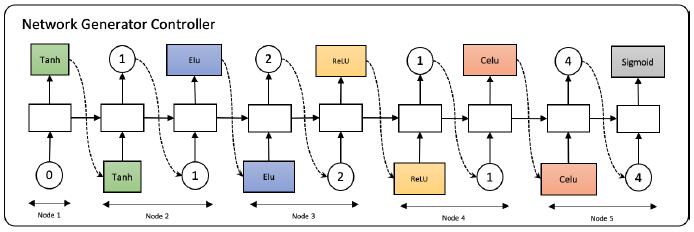 AutoCaption: Image Captioning with Neural Architecture SearchZhu, Xinxin, Wang, Weining, Guo, Longteng, and Liu, JingIn arxiv 2020 (Under Review)
AutoCaption: Image Captioning with Neural Architecture SearchZhu, Xinxin, Wang, Weining, Guo, Longteng, and Liu, JingIn arxiv 2020 (Under Review)Image captioning transforms complex visual information into abstract natural language for representation, which can help computers understanding the world quickly. However, due to the complexity of the real environment, it needs to identify key objects and realize their connections, and further generate natural language. The whole process involves a visual understanding module and a language generation module, which brings more challenges to the design of deep neural networks than other tasks. Neural Architecture Search (NAS) has shown its important role in a variety of image recognition tasks. Besides, RNN plays an essential role in the image captioning task. We introduce a AutoCaption method to better design the decoder module of the image captioning where we use the NAS to design the decoder module called AutoRNN automatically. We use the reinforcement learning method based on shared parameters for automatic design the AutoRNN efficiently. The search space of the AutoCaption includes connections between the layers and the operations in layers both, and it can make AutoRNN express more architectures. In particular, RNN is equivalent to a subset of our search space. Experiments on the MSCOCO datasets show that our AutoCaption model can achieve better performance than traditional hand-design methods. Our AutoCaption obtains the best published CIDEr performance of 135.8% on COCO Karpathy test split. When further using ensemble technology, CIDEr is boosted up to 139.5%.
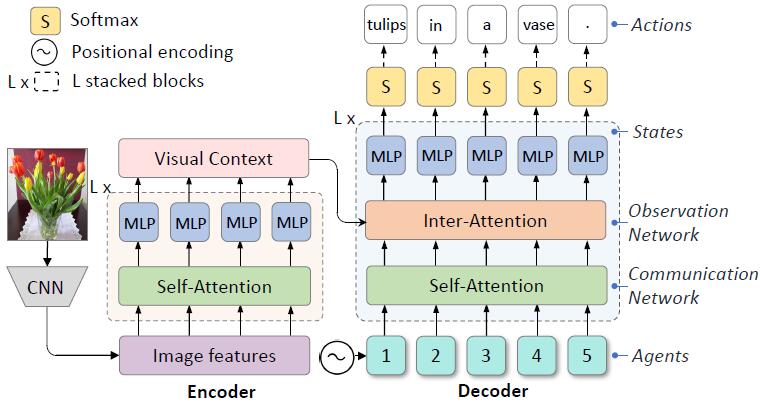 Non-Autoregressive Image Captioning with Counterfactuals-Critical Multi-Agent LearningIn IJCAI 2020
Non-Autoregressive Image Captioning with Counterfactuals-Critical Multi-Agent LearningIn IJCAI 2020Most image captioning models are autoregressive, i.e. they generate each word by conditioning on previously generated words, which leads to heavy latency during inference. Recently, non-autoregressive decoding has been proposed in machine translation to speed up the inference time by generating all words in parallel. Typically, these models use the word-level cross-entropy loss to optimize each word independently. However, such a learning process fails to consider the sentence-level consistency, thus resulting in inferior generation quality of these non-autoregressive models. In this paper, we propose a Non-Autoregressive Image Captioning (NAIC) model with a novel training paradigm: Counterfactuals-critical Multi-Agent Learning (CMAL). CMAL formulates NAIC as a multi-agent reinforcement learning system where positions in the target sequence are viewed as agents that learn to cooperatively maximize a sentence-level reward. Besides, we propose to utilize massive unlabeled images to boost captioning performance. Extensive experiments on MSCOCO image captioning benchmark show that our NAIC model achieves a performance comparable to state-of-the-art autoregressive models, while brings 13.9x decoding speedup.
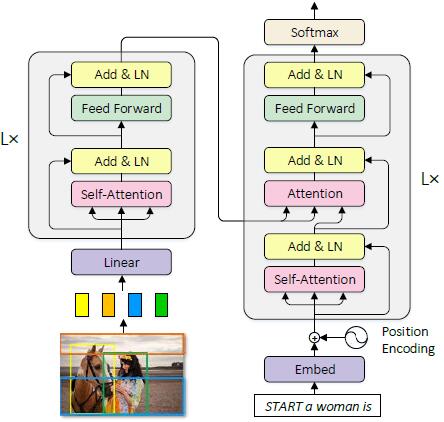 Normalized and Geometry-Aware Self-Attention Network for Image CaptioningGuo, Longteng, Liu, Jing, Zhu, Xinxin, Yao, Peng, Lu, Shichen, and Lu, HanqingIn CVPR 2020
Normalized and Geometry-Aware Self-Attention Network for Image CaptioningGuo, Longteng, Liu, Jing, Zhu, Xinxin, Yao, Peng, Lu, Shichen, and Lu, HanqingIn CVPR 2020Self-attention (SA) network has shown profound value in image captioning. In this paper, we improve SA from two aspects to promote the performance of image captioning. First, we propose Normalized Self-Attention (NSA), a reparameterization of SA that brings the benefits of normalization inside SA. While normalization is previously only applied outside SA, we introduce a novel normalization method and demonstrate that it is both possible and beneficial to perform it on the hidden activations inside SA. Second, to compensate for the major limit of Transformer that it fails to model the geometry structure of the input objects, we propose a class of Geometry-aware Self-Attention (GSA) that extends SA to explicitly and efficiently consider the relative geometry relations between the objects in the image. To construct our image captioning model, we combine the two modules and apply it to the vanilla self-attention network. We extensively evaluate our proposals on MS-COCO image captioning dataset and superior results are achieved when comparing to state-of-the-art approaches. Further experiments on three challenging tasks, i.e. video captioning, machine translation, and visual question answering, show the generality of our methods.
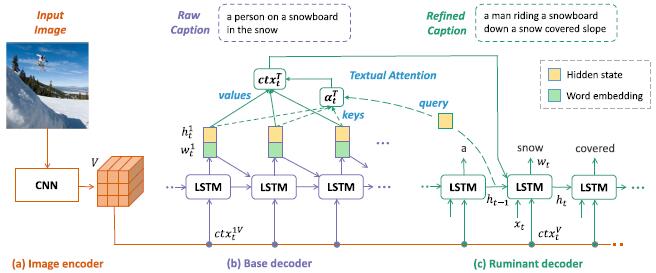 Show, Tell, and Polish: Ruminant Decoding for Image CaptioningGuo, Longteng, Liu, Jing, Lu, Shichen, and Lu, HanqingIEEE Transactions on Multimedia 2020
Show, Tell, and Polish: Ruminant Decoding for Image CaptioningGuo, Longteng, Liu, Jing, Lu, Shichen, and Lu, HanqingIEEE Transactions on Multimedia 2020The encoder-decoder framework has been the base of popular image captioning models, which typically predicts the target sentence based on the encoded source image one word at a time in sequence. However, such a single-pass decoding framework encounters two problems. First, mistakes in the predicted words cannot be corrected and may propagate to the entire sentence. Second, because the single-pass decoder cannot access the following un-generated words, it can only perform local planning to choose every single word according to the preceding words, while lacks the global planning ability as for maintaining the semantic consistency and fluency of the whole sentence. In order to address the above two problems, in this work, we design a ruminant captioning framework which contains an image encoder, a base decoder, and a ruminant decoder. Specifically, the outputs of the former/base decoder are utilized as the global information to guide the words prediction of the latter/ruminant decoder, in an attempt to mimic human polishing process. We enable jointly training of the whole framework and overcome the non-differential problem of discrete words by designing a novel reinforcement learning based optimization algorithm. Experiments on two datasets (MS COCO and Flickr30 k) demonstrate that our ruminant decoding method can bring significant improvements over traditional single-pass decoding based models and achieves state-of-the-art performance.
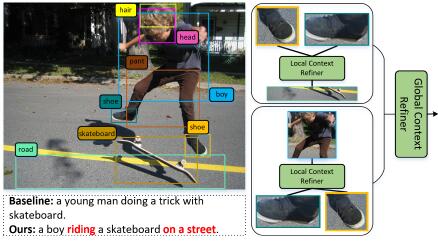 Modeling Local and Global Contexts for Image CaptioningYao, Peng, Li, Jiangyun, Guo, Longteng, and Liu, JingIn ICME 2020
Modeling Local and Global Contexts for Image CaptioningYao, Peng, Li, Jiangyun, Guo, Longteng, and Liu, JingIn ICME 2020Image captioning aims to first observe an image, most notably the involved objects that are highly context-dependent, and then depict it with a natural description. However, most of the current models solely use the isolated objects vectors as image representations, ignoring the contexts among them. In this paper, we introduce a Local-Global Context (LGC) network, endowing the independent object features with shortrange perception (local contexts) and long-range dependence (global contexts). LGC network can be viewed as feature refiner, much beneficial to reason the novel objects and verbal words for the caption decoder. The local contexts are modeled with 1-D group convolution on adjacent objects, strengthening the local connections. Still further, self-attention mechanism is utilized to model the global contexts by correlating all the local contexts. Extensive experiments on MSCOCO dataset demonstrate that LGC network can easily plug into almost any neural captioning models and significantly improve the model performance.
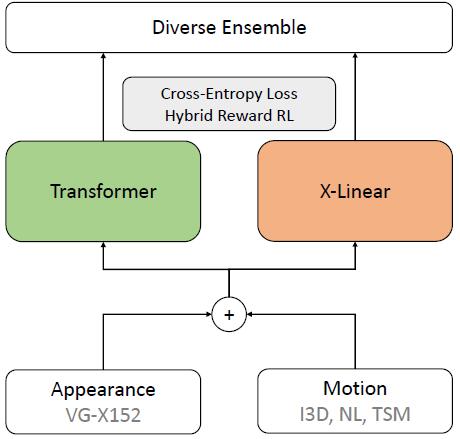 Vatex Video Captioning Challenge 2020: Multi-View Features and Hybrid Reward Strategies for Video CaptioningGuo, Longteng, Zhu, Xinxin, Yao, Peng, Lu, Shichen, Liu, Wei, and Liu, JingIn CVPR Workshop 2020
Vatex Video Captioning Challenge 2020: Multi-View Features and Hybrid Reward Strategies for Video CaptioningGuo, Longteng, Zhu, Xinxin, Yao, Peng, Lu, Shichen, Liu, Wei, and Liu, JingIn CVPR Workshop 2020This report describes our solution for the VATEX Captioning Challenge 2020, which requires generating descriptions for the videos in both English and Chinese languages. We identified three crucial factors that improve the performance, namely: multi-view features, hybrid reward, and diverse ensemble. Based on our method of VATEX 2019 challenge, we achieved significant improvements this year with more advanced model architectures, combination of appearance and motion features, and careful hyper-parameters tuning. Our method achieves very competitive results on both of the Chinese and English video captioning tracks.
2019
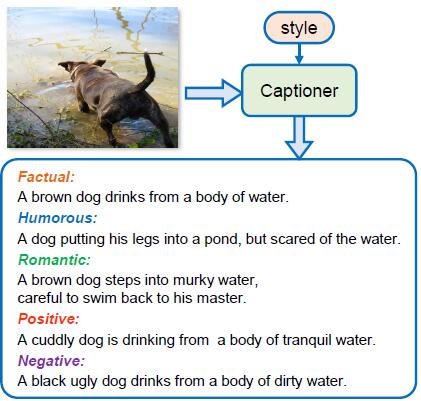 MSCap: Multi-Style Image Captioning With Unpaired Stylized TextGuo, Longteng, Liu, Jing, Yao, Peng, Li, Jiangwei, and Lu, HanqingIn CVPR 2019
MSCap: Multi-Style Image Captioning With Unpaired Stylized TextGuo, Longteng, Liu, Jing, Yao, Peng, Li, Jiangwei, and Lu, HanqingIn CVPR 2019In this paper, we propose an adversarial learning network for the task of multi-style image captioning (MSCap) with a standard factual image caption dataset and a multi-stylized language corpus without paired images. How to learn a single model for multi-stylized image captioning with unpaired data is a challenging and necessary task, whereas rarely studied in previous works. The proposed framework mainly includes four contributive modules following a typical image encoder. First, a style dependent caption generator to output a sentence conditioned on an encoded image and a specified style. Second, a caption discriminator is presented to distinguish the input sentence to be real or not. The discriminator and the generator are trained in an adversarial manner to enable more natural and human-like captions. Third, a style classifier is employed to discriminate the specific style of the input sentence. Besides, a back-translation module is designed to enforce the generated stylized captions are visually grounded, with the intuition of the cycle consistency for factual caption and stylized caption. We enable an end-to-end optimization of the whole model with differentiable softmax approximation. At last, we conduct comprehensive experiments using a combined dataset containing four caption styles to demonstrate the outstanding performance of our proposed method.
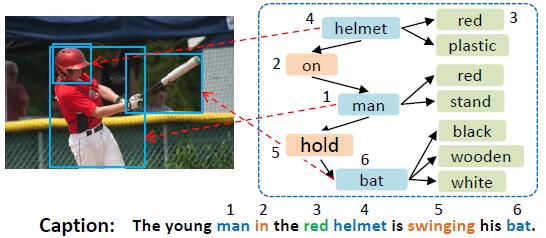 Aligning Linguistic Words and Visual Semantic Units for Image CaptioningIn ACM MM 2019 Oral
Aligning Linguistic Words and Visual Semantic Units for Image CaptioningIn ACM MM 2019 OralImage captioning attempts to generate a sentence composed of several linguistic words, which are used to describe objects, attributes, and interactions in an image, denoted as visual semantic units in this paper. Based on this view, we propose to explicitly model the object interactions in semantics and geometry based on Graph Convolutional Networks (GCNs), and fully exploit the alignment between linguistic words and visual semantic units for image captioning. Particularly, we construct a semantic graph and a geometry graph, where each node corresponds to a visual semantic unit, i.e., an object, an attribute, or a semantic (geometrical) interaction between two objects. Accordingly, the semantic (geometrical) context-aware embeddings for each unit are obtained through the corresponding GCN learning processers. At each time step, a context gated attention module takes as inputs the embeddings of the visual semantic units and hierarchically align the current word with these units by first deciding which type of visual semantic unit (object, attribute, or interaction) the current word is about, and then finding the most correlated visual semantic units under this type. Extensive experiments are conducted on the challenging MS-COCO image captioning dataset, and superior results are reported when comparing to state-of-the-art approaches.
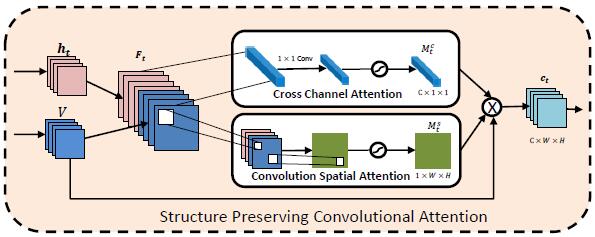 Structure Preserving Convolutional Attention for Image CaptioningLu, Shichen, Hu, Ruimin, Liu, Jing, Guo, Longteng, and Zheng, FeiApplied Sciences 2019
Structure Preserving Convolutional Attention for Image CaptioningLu, Shichen, Hu, Ruimin, Liu, Jing, Guo, Longteng, and Zheng, FeiApplied Sciences 2019In the task of image captioning, learning the attentive image regions is necessary to adaptively and precisely focus on the object semantics relevant to each decoded word. In this paper, we propose a convolutional attention module that can preserve the spatial structure of the image by performing the convolution operation directly on the 2D feature maps. The proposed attention mechanism contains two components: convolutional spatial attention and cross-channel attention, aiming to determine the intended regions to describe the image along the spatial and channel dimensions, respectively. Both of the two attentions are calculated at each decoding step. In order to preserve the spatial structure, instead of operating on the vector representation of each image grid, the two attention components are both computed directly on the entire feature maps with convolution operations. Experiments on two large-scale datasets (MSCOCO and Flickr30K) demonstrate the outstanding performance of our proposed method.
 Boosted Transformer for Image CaptioningLi, Jiangyun, Yao, Peng, Guo, Longteng, and Zhang, WeicunApplied Sciences 2019
Boosted Transformer for Image CaptioningLi, Jiangyun, Yao, Peng, Guo, Longteng, and Zhang, WeicunApplied Sciences 2019Image captioning attempts to generate a description given an image, usually taking Convolutional Neural Network as the encoder to extract the visual features and a sequence model, among which the self-attention mechanism has achieved advanced progress recently, as the decoder to generate descriptions. However, this predominant encoder-decoder architecture has some problems to be solved. On the encoder side, without the semantic concepts, the extracted visual features do not make full use of the image information. On the decoder side, the sequence self-attention only relies on word representations, lacking the guidance of visual information and easily influenced by the language prior. In this paper, we propose a novel boosted transformer model with two attention modules for the above-mentioned problems, i.e., “Concept-Guided Attention” (CGA) and “Vision-Guided Attention” (VGA). Our model utilizes CGA in the encoder, to obtain the boosted visual features by integrating the instance-level concepts into the visual features. In the decoder, we stack VGA, which uses the visual information as a bridge to model internal relationships among the sequences and can be an auxiliary module of sequence self-attention. Quantitative and qualitative results on the Microsoft COCO dataset demonstrate the better performance of our model than the state-of-the-art approaches.
 Multi-View Features and Hybrid Reward Strategies for Vatex Video Captioning Challenge 2019Guo, Longteng, Zhu, Xinxin, Yao, Peng, Liu, Jing, and Lu, HanqingIn ICCV Workshop 2019
Multi-View Features and Hybrid Reward Strategies for Vatex Video Captioning Challenge 2019Guo, Longteng, Zhu, Xinxin, Yao, Peng, Liu, Jing, and Lu, HanqingIn ICCV Workshop 2019This document describes our solution for the VATEX Captioning Challenge 2019, which requires generating descriptions for the videos in both English and Chinese languages. We identified three crucial factors that improve the performance, namely: multi-view features, hybrid reward, and diverse ensemble. Our method achieves the 2nd and the 3rd places on the Chinese and English video captioning tracks, respectively.
2018
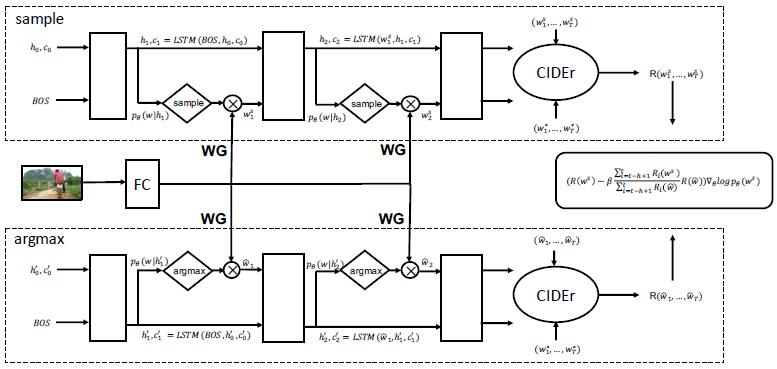 Image Captioning with Word Gate and Adaptive Self-Critical LearningZhu, Xinxin, Li, Lixiang, Liu, Jing, Guo, Longteng, Fang, Zhiwei, Peng, Haipeng, and Niu, XinxinApplied Sciences 2018
Image Captioning with Word Gate and Adaptive Self-Critical LearningZhu, Xinxin, Li, Lixiang, Liu, Jing, Guo, Longteng, Fang, Zhiwei, Peng, Haipeng, and Niu, XinxinApplied Sciences 2018Although the policy-gradient methods for reinforcement learning have shown significant improvement in image captioning, how to achieve high performance during the reinforcement optimizing process is still not a simple task. There are at least two difficulties: (1) The large size of vocabulary leads to a large action space, which makes it difficult for the model to accurately predict the current word. (2) The large variance of gradient estimation in reinforcement learning usually causes severe instabilities in the training process. In this paper, we propose two innovations to boost the performance of self-critical sequence training (SCST). First, we modify the standard long short-term memory (LSTM)based decoder by introducing a gate function to reduce the search scope of the vocabulary for any given image, which is termed the word gate decoder. Second, instead of only considering current maximum actions greedily, we propose a stabilized gradient estimation method whose gradient variance is controlled by the difference between the sampling reward from the current model and the expectation of the historical reward. We conducted extensive experiments, and results showed that our method could accelerate the training process and increase the prediction accuracy. Our method was validated on MS COCO datasets and yielded state-of-the-art performance.